複数のsortされたリストをマージする
Intro
業務の中で、複数のDataFrameの相違を得る必要があった。
TL; DR
- 複数のdfの相違を見ることが目的
- そのために、複数のsortされたリストをマージするアルゴリズムを作成した
Question
pythonのpandasにおいて、以下のようなDataFrameを差分比較して、その次に示す結果を得たい。
Input
Input
df0
| content_key | content_id | content_name |
|---|---|---|
| S010 | P001 | SORT |
| S020 | P002 | |
| AAAA | Q001 | |
| S025 | P002 | JOIN |
| AAAA | Q001 | |
| S030 | P003 | AGGREGATE |
df1
| content_key | content_id | content_name |
|---|---|---|
| S010 | P001 | SORT |
| S020 | P002 | |
| AAAA | Q001 | |
| AAAA | Q001 | |
| S030 | P003 | AGGREGATE |
| S035 | P004 | JOIN |
df2
| content_key | content_id | content_name |
|---|---|---|
| AABB | Q002 | |
| S010 | P001 | SORT |
| S015 | P012 | |
| S020 | P032 | |
| AAAA | Q001 | |
| S026 | P022 | JOIN |
| AAAA | Q001 | |
| S030 | P003 | AGGREGATE |
Results
Results
df_merge0
| content_key | content_id | content_name |
|---|---|---|
| AABB | - | |
| S010 | P001 | SORT |
| S015 | - | |
| S020 | P002 | |
| AAAA | Q001 | |
| S025 | P002 | JOIN |
| S026 | - | - |
| AAAA | Q001 | |
| S030 | P003 | AGGREGATE |
| S035 | - | - |
df_merge1
| content_key | content_id | content_name |
|---|---|---|
| AABB | - | |
| S010 | P001 | SORT |
| S015 | - | |
| S020 | P002 | |
| AAAA | Q001 | |
| S025 | - | - |
| S026 | - | - |
| AAAA | Q001 | |
| S030 | P003 | AGGREGATE |
| S035 | P004 | JOIN |
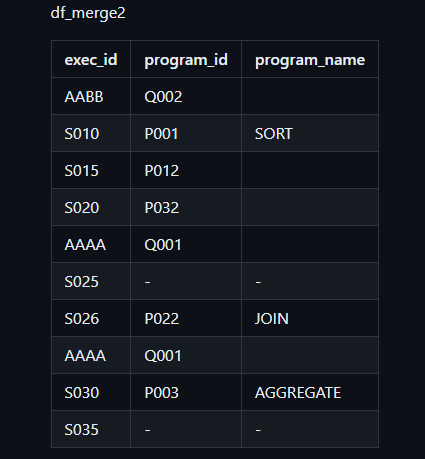
df_merge2
| content_key | content_id | content_name |
|---|---|---|
| AABB | Q002 | |
| S010 | P001 | SORT |
| S015 | P012 | |
| S020 | P032 | |
| AAAA | Q001 | |
| S025 | - | - |
| S026 | P022 | JOIN |
| AAAA | Q001 | |
| S030 | P003 | AGGREGATE |
| S035 | - | - |
merge_sorted_listsとは
上記のQuestionの結果を得るためには、df0からdf2の微妙に異なるcontent_keyから得られるリストは以下の条件を満たす必要がある。
(後述するが、単純なOuter Joinでは理想の結果を得られない)
条件1: 元の任意のlistはmerged_listから部分列を取り除いて得られる
これだけが条件なら、そのまま連結してしまうのが早い。
1 | |
ただ、これは各dfの相違を見るという目的を満たさない。
df0とdf1はcontent_keyで見ると、S025とS035が異なるだけだからだ。
つまり、これらのcontent_keyをmergeしたlist_df01は下記のようになってほしい。
1 | |
これをdf0とdf1から具体的に人間が作成するのは簡単だが、
抽象的なアルゴリズムを作成するとなると、難しい。
(というか、調べても出てこなかった。そんなに需要ない話か?)
少しあいまいだが、条件1に加えて、以下を条件としよう。
条件2: 既存のmerged_listに新たにlistをmergeする場合、一致する部分はできる限り共有する (ただし、順序関係は保つ)
一般的なmergeとの比較
一般にもlistをmergeする方法はある。それらとの比較をしてみよう。
Extend
単純にlistをつなげていく方法。
これは明らかに条件1を満たすが、一切部分を共有しておらず、条件2を満たすとはいえない。
1 | |
outer join
dbでよく使われるouter joinを使う方法。
そもそもOuter Joinは、df全体をmergeしつつ、その相違を見るという観点では最も想定される方法だ。
実際にやってみよう。
1 | |
| content_key | content_id_0 | content_name_0 | content_id_1 | content_name_1 | |
|---|---|---|---|---|---|
| 0 | AAAA | Q001 | Q001 | ||
| 1 | AAAA | Q001 | Q001 | ||
| 2 | AAAA | Q001 | Q001 | ||
| 3 | AAAA | Q001 | Q001 | ||
| 4 | S010 | P001 | SORT | P001 | SORT |
| 5 | S020 | P002 | P002 | ||
| 6 | S025 | P002 | JOIN | nan | nan |
| 7 | S030 | P003 | AGGREGATE | P003 | AGGREGATE |
| 8 | S035 | nan | nan | P004 | JOIN |
順序がめちゃくちゃだ!!
条件1を満たしていなかった。
当初の試行錯誤では、この外部連結で元の順序関係をどうにか保てないかと考えた。
1 | |
| content_key | content_id_df0 | content_name_df0 | content_id_df1 | content_name_df1 | |
|---|---|---|---|---|---|
| 0 | S010 | P001 | SORT | P001 | SORT |
| 1 | S020 | P002 | P002 | ||
| 2 | AAAA | Q001 | Q001 | ||
| 3 | AAAA | Q001 | Q001 | ||
| 4 | S025 | P002 | JOIN | nan | nan |
| 5 | AAAA | Q001 | Q001 | ||
| 6 | AAAA | Q001 | Q001 | ||
| 7 | S030 | P003 | AGGREGATE | P003 | AGGREGATE |
| 8 | S035 | nan | nan | P004 | JOIN |
AAAAが重複しているが、まあまあ悪くない。
しかし、ここでdf0とdf2で外部連結すると下記の通りになる。
| content_key | content_id_df0 | content_name_df0 | content_id_df1 | content_name_df1 | |
|---|---|---|---|---|---|
| 0 | S010 | P001 | SORT | P001 | SORT |
| 1 | S020 | P002 | P032 | ||
| 2 | AAAA | Q001 | Q001 | ||
| 3 | AAAA | Q001 | Q001 | ||
| 4 | S025 | P002 | JOIN | nan | nan |
| 5 | AAAA | Q001 | Q001 | ||
| 6 | AAAA | Q001 | Q001 | ||
| 7 | S030 | P003 | AGGREGATE | P003 | AGGREGATE |
| 8 | AABB | nan | nan | Q002 | |
| 9 | S015 | nan | nan | P012 | |
| 10 | S026 | nan | nan | P022 | JOIN |
先頭に来るべきAABBや、途中で挿入されるべきS015やS026が、順序関係を保てない。
これはsortの基準としてdf0のindexを使っているためだ。
df0に含まれないcontent_keyが挿入されると、それらのindexはnanになり、後ろに回される。
df2のindexをsortのkeyとして併用しようとしても、df0からのindexではnanになるため、結局後ろに回される。
df2のindexをsortのkeyとしても、df2に含まれないcontent_keyに対応するindexはnanになる。状況は変わらない。
1 | |
| content_key | content_id_df0 | content_name_df0 | index_df0 | content_id_df2 | content_name_df2 | index_df2 | |
|---|---|---|---|---|---|---|---|
| 0 | S010 | P001 | SORT | 0 | P001 | SORT | 1 |
| 1 | S020 | P002 | 1 | P032 | 3 | ||
| 2 | AAAA | Q001 | 2 | Q001 | 4 | ||
| 3 | AAAA | Q001 | 2 | Q001 | 6 | ||
| 4 | S025 | P002 | JOIN | 3 | nan | nan | nan |
| 5 | AAAA | Q001 | 4 | Q001 | 4 | ||
| 6 | AAAA | Q001 | 4 | Q001 | 6 | ||
| 7 | S030 | P003 | AGGREGATE | 5 | P003 | AGGREGATE | 7 |
| 8 | AABB | nan | nan | nan | Q002 | 0 | |
| 9 | S015 | nan | nan | nan | P012 | 2 | |
| 10 | S026 | nan | nan | nan | P022 | JOIN | 5 |
すべてのcontent_keyを順序関係を保ちながら含むlistがあれば問題は解決する。
それこそまさに、merge_sorted_listsである。
merge_sorted_listsの実装
ChatGPTにプロンプトを投げたのち、手動で修正することで以下を得た。
1 | |
Prompt for ChatGPT
[1,2,3,4,7,10,9,11,5]と
[1,2,3,4,6,10,11,20]から
[1,2,3,4,6,7,10,9,11,5,20]を得るようにlistを並び順を考慮してmergeするpythonのscriptが欲しい
list1とlist2の比較は数値の大小では比較しない
list1とlist2を混ぜたmaster listがあると仮定して、行う
master listがあると仮定して、master listを見つけたい
まとめ
merge_sorted_listsは、複数のsortされたリストをマージする際に、それらの相違を見つけるためのアルゴリズムである。